Google has created a red team that focuses on artificial intelligence (AI) systems and it has published a report providing an overview of common types of attacks and the lessons learned.
The company announced its AI Red Team just weeks after introducing Secure AI Framework (SAIF), which is designed to provide a security framework for the development, use and protection of AI systems.
Google’s new report highlights the importance of red teaming for AI systems, the types of AI attacks that can be simulated by red teams, and lessons for other organizations that might consider launching their own team.
“The AI Red Team is closely aligned with traditional red teams, but also has the necessary AI subject matter expertise to carry out complex technical attacks on AI systems,” Google said.
The company’s AI Red Team takes the role of adversaries in testing the impact of potential attacks against real world products and features that use AI.
For instance, take prompt engineering, a widely used AI attack method where prompts are manipulated to force the system to respond in a specific manner desired by the attacker.
In an example shared by Google, a webmail application uses AI to automatically detect phishing emails and warn users. The security feature uses a general purpose large language model (LLM) — ChatGPT is the most well-known LLM — to analyze an email and classify it as legitimate or malicious.
An attacker who knows that the phishing detection feature uses AI can add to their malicious email an invisible paragraph (by setting its font to white) that contains instructions for the LLM, telling it to classify the email as legitimate.
“If the web mail’s phishing filter is vulnerable to prompt attacks, the LLM might interpret parts of the email content as instructions, and classify the email as legitimate, as desired by the attacker. The phisher doesn’t need to worry about negative consequences of including this, since the text is well-hidden from the victim, and loses nothing even if the attack fails,” Google explained.
Another example involves the data used to train the LLM. While this training data has largely been stripped of personal and other sensitive information, researchers have shown that they were still able to extract personal information from an LLM.
Training data can also be abused in the case of email autocomplete features. An attacker could trick the AI into providing information about an individual using specially crafted sentences that the autocomplete feature completes with memorized training data that could include private information.
For instance, an attacker enters the text: “John Doe has been missing a lot of work lately. He has not been able to come to the office because…”. The autocomplete feature, based on training data, could complete the sentence with “he was interviewing for a new job”.
Locking down access to an LLM is also important. In an example provided by Google, a student gains access to an LLM specifically designed to grade essays. The model is able to prevent prompt injection, but access has not been locked down, allowing the student to train the model to always assign the best grade to papers that contain a specific word.
Google’s report has several other examples of types of attacks that an AI red team can put to the test.

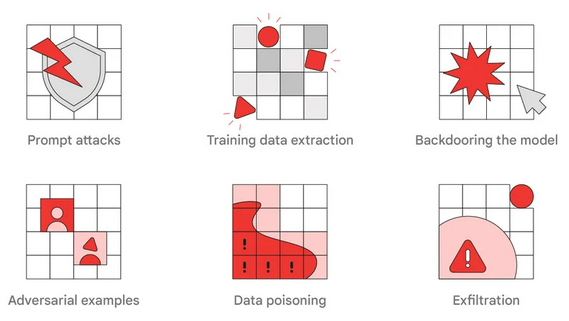
As for lessons learned, Google recommends for traditional red teams to join forces with AI experts to create realistic adversarial simulations. It also points out that addressing the findings of red teams can be challenging and some issues may not be easy to fix.
Traditional security controls can be efficient in mitigating many risks. For example, ensuring that systems and models are properly locked down helps protect the integrity of AI models, preventing backdoors and data poisoning.
On the other hand, while some attacks on AI systems can be detected using traditional methods, others, such as content issues and prompt attacks, could require layering multiple security models.
Related: Now’s the Time for a Pragmatic Approach to New Technology Adoption
Related: ChatGPT Hallucinations Can Be Exploited to Distribute Malicious Code Packages
Related: AntChain, Intel Create New Privacy-Preserving Computing Platform for AI Training